Data Store Service Overview
The Data Store service is a pivotal microservice within our architecture, serving as the central hub for all database updates and acting as the custodian of critical data. Its primary responsibilities include managing data integrity, ensuring transactional consistency, and facilitating efficient data access for other microservices within the ecosystem.
Key Responsibilities
Database Updates
The Data Store service is responsible for executing all database operations, including create, read, update, and delete (CRUD) operations. This centralization of database interactions helps maintain data integrity and ensures that all changes are tracked and managed effectively.
Custodian of Data
As the custodian, the Data Store service safeguards the data, ensuring that it is stored securely and is accessible only to authorized services. This includes implementing access controls and data validation mechanisms to prevent unauthorized access and maintain data quality.
Database Schema Initialization
The service also handles the initialization of the database schema. This is achieved using init containers, which are specialized containers that run before the main application starts. Init containers are used to set up the database structure, including tables, indexes, and relationships, ensuring that the database is ready to handle transactional updates from the outset.
Communication Modes
The Data Store service supports two primary modes of communication, allowing consumer services to interact with it based on their specific needs:
Direct REST API Communication
- The Data Store service exposes a RESTful API that allows consumer services to perform synchronous operations. This mode is particularly useful for scenarios where Kafka is not present (development areas) and quick testing for the functionalities. This also allows us to have a rollback and a secondary mechanism in case of any Kafka failures.
- REST API communication ensures that the consumer receives the most recent data state immediately after an operation, providing strong consistency guarantees.
Kafka-Based Communication
- In the higher environments, where scalability matters, the Data Store service uses communication via Kafka, a distributed streaming platform. This mode is configurable by the consumer services, allowing them to choose Kafka for asynchronous communication.
- Kafka enables the system to scale effectively, handling a high volume of messages and allowing for decoupled communication between services. This is particularly beneficial in production environments like Navida, where scalability and performance are critical.
Eventual Consistency Challenges
While Kafka enhances scalability and allows for high-throughput data processing, it introduces certain challenges, particularly concerning eventual consistency:
Single Consumer Responsibility
- In the current architecture, there is only one consumer microservice responsible for processing all messages from Kafka and performing the actual database updates. This centralization can lead to bottlenecks, especially during peak loads, and cron jobs running in parallel and updating bulk records at a time. As the consumer, the Data Store will be processing each message sequentially.
Eventual Consistency Issues
- Due to the asynchronous nature of Kafka communication, there can be delays in processing updates. As a result, different parts of the system may see different versions of the data at any given time. This phenomenon is known as eventual consistency, where the system guarantees that, given enough time, all updates will propagate and all nodes will eventually become consistent.
- The latency associated with transactional updates can lead to scenarios where consumers querying the Data Store may receive stale data, impacting the user experience and potentially leading to inconsistencies in application behavior.
Mitigation Strategies
To address these eventual consistency issues, it is essential to implement strategies that can help manage and mitigate the impact of latency. This may include:
- Compensating Transactions: Implementing mechanisms to reconcile discrepancies when they arise, ensuring that the system can adjust for inconsistencies over time.
- Waiting Producers: In the Kafka library present in Open Contract, we have a ReplyWaitingMechanism that ensures the messages to Kafka are processed and receive a successful response from the consumer before returning to the consumer for further processing and reads.
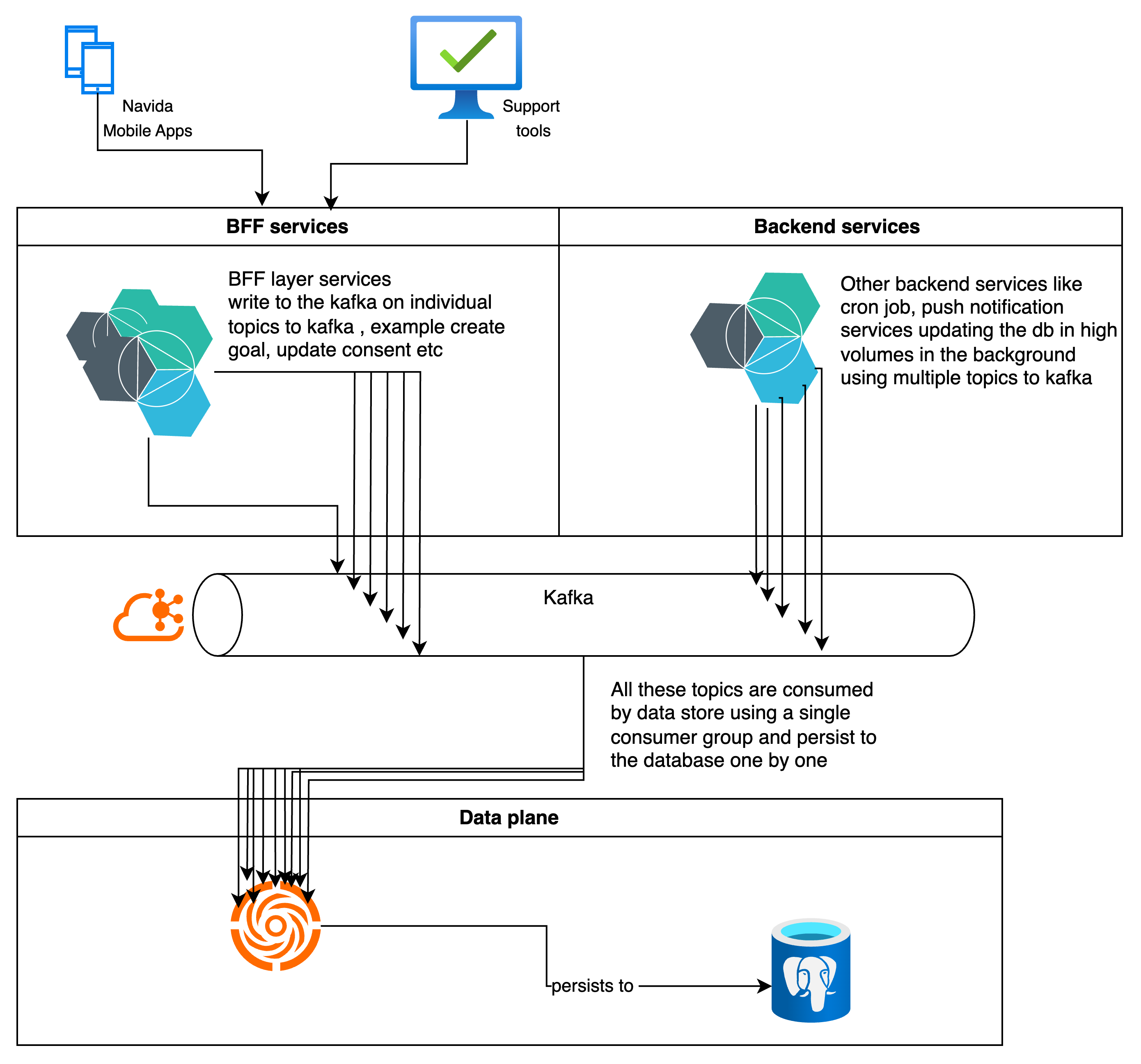
The Data Store service plays a crucial role in the overall architecture, serving as the backbone for database interactions and data management. It is essential to remain vigilant about the challenges posed by eventual consistency and latency, implementing appropriate strategies to ensure that the system remains robust, reliable, and responsive to the needs of its consumers.