Tenant Context
Overview
Navida is designed as a highly scalable platform, which means it can efficiently handle growth in both its infrastructure and functional capabilities. This scalability is crucial for accommodating increasing workloads and expanding functionalities without compromising performance.
Multi-Tenant Architecture
One of the key features of Navida is its multi-tenant architecture. This design allows multiple clients (AOKs) to use the same platform while keeping their data and configurations separate. The multi-tenant approach simplifies the onboarding process for new clients, enabling them to integrate into the platform quickly and efficiently. This rapid onboarding is essential for businesses that need to adapt to changing market conditions or customer demands.
Infrastructure Model
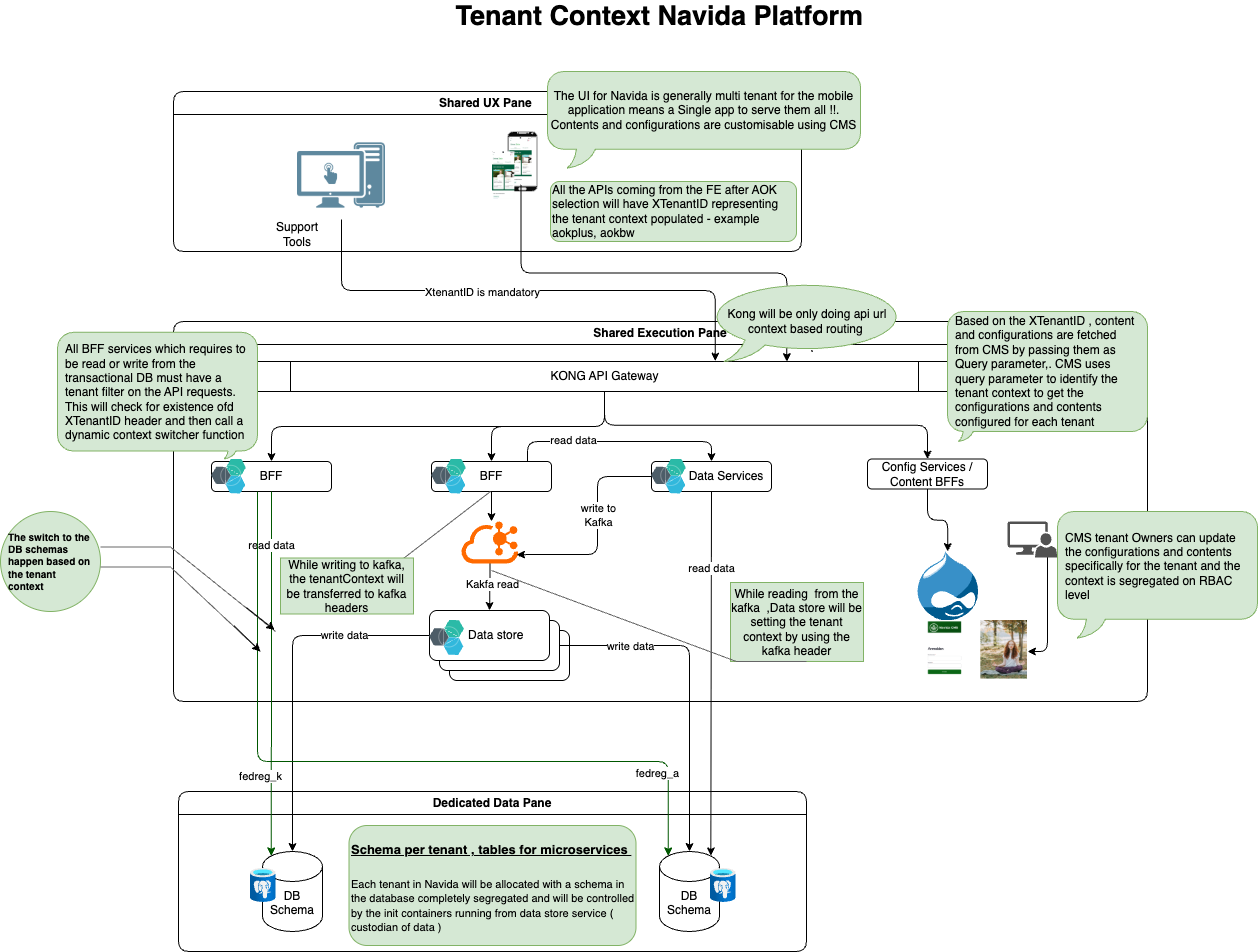
Currently, Navida operates on a shared compute infrastructure with a dedicated data model. This means that while the backend microservices, that make up the platform—run in a shared environment, each tenant's transactional data is stored separately. This setup allows for efficient resource utilization, as multiple tenants can share the same computing resources without interfering with each other's operations.
Execution Pane and Traffic Management
The execution pane of Navida is designed to handle incoming traffic from all tenants through a shared nodes of microservices . This shared node processes requests regardless of which tenant is making them, facilitating efficient traffic management and resource allocation. This design choice helps in optimizing performance and reducing latency, as resources can be dynamically allocated based on demand.
Data Storage Model
Regarding data storage, Navida currently employs a "schema per tenant" model. This means that each tenant has its own database schema, which allows for customization and flexibility in how data is structured and accessed. However, this model is also configurable, meaning that if a tenant requires it, Navida can transition to a "database per tenant" model on demand. This flexibility ensures that the platform can meet varying needs and preferences of different tenants, providing them with the level of isolation and customization they require.
Runtime execution :
When onboarding to Navida Mobile application , The end user need to select the AOK tenant and this will be used to identify tenant context and then network module of the native mobile application set an HTTP header called XtenantID. For ll the API calls here after to the backend services will contain this HTTP header
examples :
- XTenantId : aokplus
- XTenantId : aokbw
This header is also required for support tool UIs or any API-based integration with the Navida platform to ensure the correct tenant context for transactional read and write operations.
All incoming traffic to Navida backend systems is managed through a single entry point: the Kong API gateway. The gateway handles traffic routing to the appropriate Kubernetes services based on the API URL context (for example, /consent/api/v1 is routed to the consent service).
When backend services receive API requests, they invoke a tenant filter method that checks for the presence of the XTenantID header and sets the tenant context accordingly. If the header is missing, the system defaults to the default tenant mentioned in the helm configurations. This is used to see the APIs which do not need a tenant context will still work with a default configuration
refer :
ContextAwareCompletableFuture.java
The tenant filter enables the microservice to dynamically switch the database connection to the appropriate database or schema configured for each tenant. This behavior is governed by the configurations defined under resources/allTenants in the microservice source code.
Once the tenant context is established, the handling of data operations is as follows:
Read Operations:
- All read requests are directed to the database or schema associated with the identified tenant. This ensures that each tenant's data remains isolated and secure.
Write Operations:
- For write requests, since Kafka is used as the messaging layer, the tenant context must be passed along with the data.
- The XTenantID from the HTTP header is converted into a Kafka header.
- When the datastore processes the Kafka message, it reads the tenant information from the Kafka header and writes the data to the correct tenant's database or schema.
Configurations and Contents from CMS
All content, system records, and configurations managed in the CMS are already associated with the tenant context through RBAC. Each record is linked to the user ID that created it. CMS APIs use simple query parameters to identify the tenant and serve content associated with users of the specified tenant.
refer CMS API example